Tidy Tuesday - African American History
If you’re not familiar with Tidy Tuesday, it is a weekly project hosted online by the R for data science community. Every Tuesday a new dataset is released and people are encouraged to explore, analyse, and visualize it in interesting ways. This is my first week exploring tidy tuesday data. Information about the project and datasets is at the tidytuesday github. Before working with this data I watched Julia Silge’s excellent screencast and picked up some great ways to find missing values and recode data.
A Little History
I learned a lot just by looking at the data provided. I was not previously aware of the history captured in the african_names dataset - which lists the names of enslaved people that were freed as they were being illegally smuggled to the Americas. The most names were recorded at the port of Freetown in Sierra Leone before making the trans-atlantic journey. Here’s the description of the dataset excepted on the tidytuesday github page:
During the last 60 years of the trans-Atlantic slave trade, courts around the Atlantic basins condemned over two thousand vessels for engaging in the traffic and recorded the details of captives found on board including their African names. The African Names Database was created from these records, now located in the Registers of Liberated Africans at the Sierra Leone National Archives, Freetown, as well as Series FO84, FO313, CO247 and CO267 held at the British National Archives in London. Links are provided to the ships in the Voyages Database from which the liberated Africans were rescued, as well as to the African Origins site where users can hear the names pronounced and help us identify the languages in which they think the names are used.
| Name | african_names |
| Number of rows | 91490 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| character | 6 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| name | 0 | 1.00 | 2 | 24 | 0 | 62330 | 0 |
| gender | 12878 | 0.86 | 3 | 5 | 0 | 4 | 0 |
| ship_name | 1 | 1.00 | 2 | 59 | 0 | 443 | 0 |
| port_disembark | 0 | 1.00 | 6 | 19 | 0 | 5 | 0 |
| port_embark | 1126 | 0.99 | 4 | 31 | 0 | 59 | 0 |
| country_origin | 79404 | 0.13 | 3 | 31 | 0 | 563 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id | 0 | 1.00 | 62122.02 | 51305.07 | 1.0 | 22935.25 | 45822.5 | 101263.8 | 199932 | ▇▆▃▁▂ |
| voyage_id | 0 | 1.00 | 17698.25 | 82016.88 | 557.0 | 2443.00 | 2871.0 | 3601.0 | 500082 | ▇▁▁▁▁ |
| age | 1126 | 0.99 | 18.89 | 8.60 | 0.5 | 11.00 | 20.0 | 26.0 | 77 | ▆▇▁▁▁ |
| height | 4820 | 0.95 | 58.61 | 6.84 | 0.0 | 54.00 | 60.0 | 64.0 | 85 | ▁▁▂▇▁ |
| year_arrival | 0 | 1.00 | 1831.40 | 9.52 | 1808.0 | 1826.00 | 1832.0 | 1837.0 | 1862 | ▂▆▇▃▁ |
## # A tibble: 5 x 2
## # Groups: port_disembark [5]
## port_disembark n
## <chr> <int>
## 1 Freetown 81009
## 2 Havana 10058
## 3 Bahamas unspecified 183
## 4 Kingston, Jamaica 144
## 5 St. Helena 96From this output we can see that country_origin has the most missing data by far. There’s a clue about this in the description of the data above, which mentions the African Origins site, where users can hear the names pronounced and help identify the languages in which they think the names are used.
So the people who were liberated were from such different cultures that the original documentarians could not speak the same language or determine where they originally came from. We can see that about 81,000 people were freed in Freetown (This now makes sense - again learning lots here). About 10,000 people were freed in Havana, Cuba, and many less in other locations in the caribbean.
The age variable includes entries from a 6-month old child to a 77 year old person. The gender variable has 12,878 missing values and 4 options. I’ll use some of the same techniques as Julia Silge to clean up this data.
african_names %>%
group_by(port_disembark, year_arrival) %>%
count() %>%
arrange(desc(year_arrival)) %>%
ggplot(aes(x = year_arrival, y = n, color = port_disembark)) + geom_line(alpha = 0.6, size = 2) + geom_point(alpha = 0.6)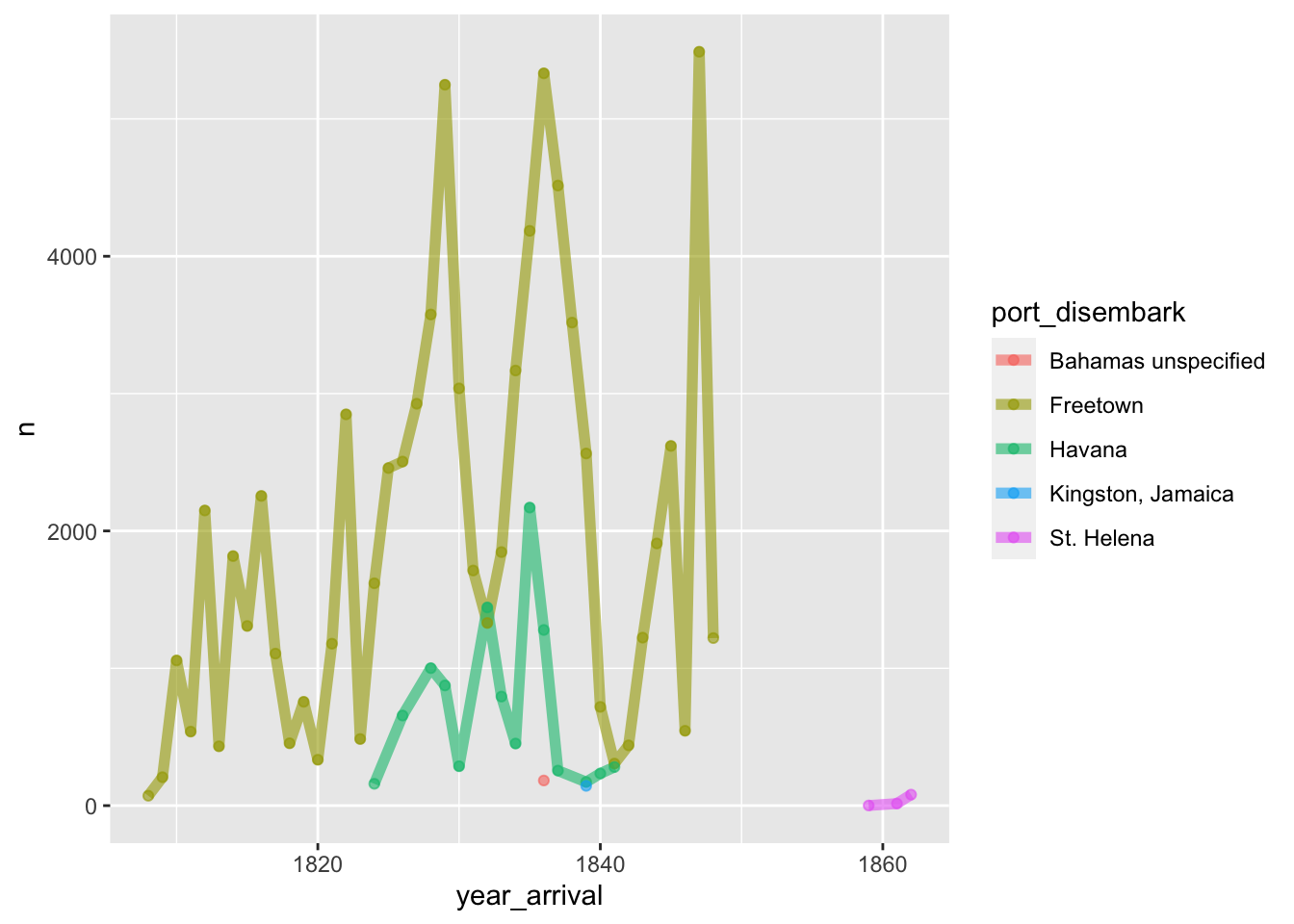
We can see that the majority of liberations occured in Freetown. I wonder if the ships had stopped going to Freetown by 1849, or if there was less enforcement, or if they stopped being recorded. Similary, I wonder what the policies were in each of the other ports that made them free enslaved Africans for the time periods reflected in this data.
Liz McConnell
Graduate Student, CSU Center for Contaminant Hydrology
My research interests include contaminant fate and transport, data analysis using statistics and machine learning, R programming, and geospatial analysis.